
Introduction
SQL Server 2016 is yet to be released, but you can download the CTP versions. The mostly anticipated and marveled feature is Always Encrypted. Let me discuss few bits of this feature before getting into the technical side of it.
I got to know this right after reading an article about Microsoft had applied some court case to safeguard the information of one of its users, from the US laws. This is highly appreciated and I personally feel that Microsoft is at the forefront of protecting customer data. And I made a tweet.

If customer can secure their data without any control of public cloud vendors, even in the situations like powerful unauthorized people gaining access to your data results in reduced data theft. And it solves a headache for the public cloud vendors as well.
How it works
SQL Server 2016 Always Encrypted is a feature which allows the encryption and the decryption of the data in the client side, rather than in the database server itself. Since the encryption happens in the client side using a client driver data is secured not only at rest but also at transit, this makes the feature takes its pride name Always Encrypted.
Always Encrypted works as follows.
-
First we have to create Column Encryption Keys (CEK) and Column Master Keys (CMK) in the Always Encrypted section of the database

-
CEKs are symmetric keys and CMKs are asymmetric keys.
-
CEKs are stored in SQL Server where CMKs are stored outside the SQL Server. Read this MSDN article to get information about how to create these keys.
-
Create database with the table and specify the columns to be encrypted. Note that the encryption type (deterministic or randomized), encryption algorithm and the CEK to be used are specified.

-
In the demo I’ve created the CMK in the local certificate store of the machine, but you can keep the CMK wherever possible. Because SQL Server stores only the meta data of the CMK.
-
Now the database is ready. We need .NET 4.6 client application to access the data in the Always Encrypted enabled database. I summarized everything in this image.

-
Application sends an INSERT statement, driver intercepts the statement and identifies the database it talks is an Always Encrypted feature enabled database. This identification happens because of the connection string property Column Encryption Setting=Enabled. So the driver asks the database to send the details of the encryption for the specific table.
-
SQL Server returns column details, encrypted values of the CEK, CMK name and the path.
-
Client driver retrieves the CMK using the meta received from the SQL Server. In this step driver gets the private key of the CMK, which is used to decrypt the encrypted CEK. (CEK is encrypted using CMK’s public key during the creation of CEK in the SQL Server, also the CEK is signed by the private key of the CMK) SQL Server does not store the CMK’s private key.
-
Client driver encrypts the data using the decrypted CEK and send it to the SQL Server.
- Read operations also work similar as SQL Server send the encrypted data along with the encryption details and CMK meta data information. Client driver then retrieves the CMK decrypts the CEK and the decrypts the data.
- Client driver implements possible caching of the keys for performance.
Sample .NET application code for the above table

Management Features
You can see the definitions of the CMKs using this command. SQL Server stores the meta data of the CMKs


You can see the definitions of the CEKs using this command


Joining the above two along with the sys.column_encryption_key_values we can get the association relationship.
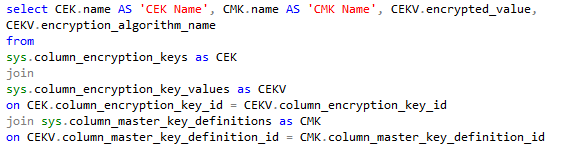

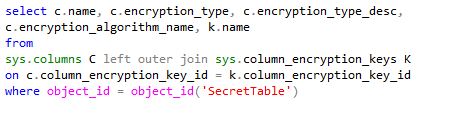
You can execute the following command to get the Always Encrypted meta data for the table.

Other useful reads
http://www.infoq.com/news/2015/06/SQL-Server-Always-Encrypted (read the comments for known FAQs)
http://blogs.msdn.com/b/sqlsecurity/archive/2015/06/04/getting-started-with-always-encrypted.aspx (Getting started with Always Encrypted)
http://sqlperformance.com/2015/08/sql-server-2016/perf-impact-always-encrypted (Performance of Always Encrypted)
You can use Azure Key Vault as the CMK store
https://thuru.net/2015/05/30/azure-key-vault-setup-and-usage-scenarios/ (Introduction to Azure Key Vault)
http://blogs.msdn.com/b/sqlsecurity/archive/2015/09/25/creating-an-ad-hoc-always-encrypted-provider-using-azure-key-vault.aspx?wt.mc_id=WW_CE_DM_OO_SCL_TW (Creating custom CMK provider, using Azure Key Vault)



































