
Planning the service communication and the cluster setup is one of the important items we should do when developing on Service Fabric (SF). In this article I have tried my best to stick to the minimalist options in setting up the cluster whilst sufficient details by eliminating the common doubts. The motive behind this research is to find the optimum cluster with little amount of development and ops time.
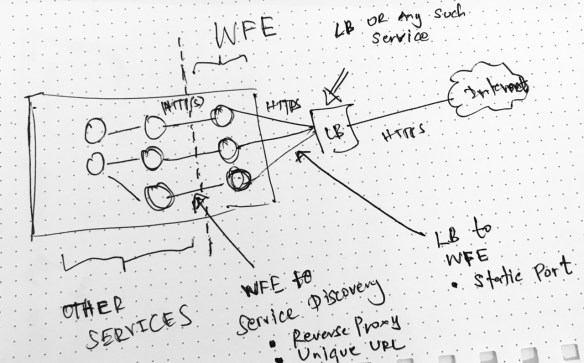
Layering WFE Services
Rule #1 : It is not recommended to open the services to the Internet. You would use a either a Load Balancer (LB) or a Gateway service. In on-prem implementations mostly this would be a LB and your cluster will reside behind a firewall.
The services mapped or connected to the LB act as the Web Front End (WFE) services. In most cases these are stateless services .
Rule #2 : LB needs to find the WFE services so WFE services should have static ports. LB (based on the selection) will have a direct or configured port mapping to these WFE services.
When you create a ASP.NET Core stateless service, Visual Studio (VS) will create the service with following aspects.
- VS will assign a static port to the service.
- Service Instance is set to 1 in in both Local.1Node.xml and Local.5Node.xml.
- Service Instance is -1 in Cloud.xml
- Kestrel Service listener
- ServiceFabricIntegrationOption set to None
Since Kestrel does not support port sharing, in the local development environment the Kestrel based stateless services are set to have only one instance whenever a port has been specified.
In you development machine, if you specify an instance which results higher than 1 while a port is specified in the ServiceManifest.xml for service which Kestrel listener, then you will get the following famous SF error.
Error event: SourceId='System.FM', Property='State'. Partition is below target replica or instance count
The above error is about, Failover Manager (FM) complaining that SF cannot create replicas as requested. In FM’s point of view, there’s a request to create more instances but due to port sharing issue in Kestrel, SF cannot create more than one instance. This is the same error you would get regardless 1 node / 5 node setup because because physically we use one machine in development.
Using HttpSys listener is an option to overcome this issue. In order to use the HttpSys listener install the following NuGet package, update the listener to HttpSysCommunicationListener and the ServiceManifest.xml as below.
Install-Package Microsoft.ServiceFabric.AspNetCore.HttpSys
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() | |
| { | |
| return new ServiceInstanceListener[] | |
| { | |
| new ServiceInstanceListener(serviceContext => | |
| new HttpSysCommunicationListener(serviceContext, "GatewayHttpSysServiceEnpoint", (url, listener) => | |
| { | |
| ServiceEventSource.Current.ServiceMessage(serviceContext, $"Starting HttpSys on {url}"); | |
| return new WebHostBuilder() | |
| .UseHttpSys() | |
| .ConfigureServices( | |
| services => services | |
| .AddSingleton<StatelessServiceContext>(serviceContext)) | |
| .UseContentRoot(Directory.GetCurrentDirectory()) | |
| .UseStartup<Startup>() | |
| .UseServiceFabricIntegration(listener, ServiceFabricIntegrationOptions.None) | |
| .UseUrls(url) | |
| .Build(); | |
| })) | |
| }; |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| <Endpoints> | |
| <Endpoint Protocol="http" Name="GatewayHttpSysServiceEnpoint" Type="Input" Port="8080"/> | |
| </Endpoints> |
In fact, in the production deployments when more than one node available we can use Kestrel listener with static port mentioned in the ServiceManifest.xml with more than one instance. SF will place the instances in different nodes. This is why the instance count is set to -1 in Cloud.xml.
Here the -1 is safe, because setting a specific number for instance count while Kestrel is used in static port mode may create issues when the requested instance count exceeds the nodes available for SF to place the service.
Common Question: Can we use HttpSys listener and enable scaling ? This is possible but most cases specially in stateless services scaling number of instances is the typical scale out scenario. So there’s no point having a scale out strategy in a single node by congesting a node with many number of services, because running multiple instances in same the same node will not yield the desired throughput we need. Also in such cases Cluster Manager will not find enough nodes with UD/FD combination in order to place the instances and provide a warning message.
Do not make the mistake that I favor Kestrel over HttpSys in this article, there are specific cases where you need HttpSys over Kestrel. In Microsoft articles Kestrel being mentioned and most of the cases are given in such a way that Kestrel can be used to reach desired output regardless of its inability of handing port sharing. From ASP.NET Core point of view Kestrel is good as long as your service is not directly facing the Internet.
Best Practice : Do NOT place WFE services in all nodes. Have dedicated nodes for the WFE services (use placement strategies). This allows stronger separation between WFE nodes and internal nodes. We can also implement a firewall between WFE service nodes and internal service nodes. In another way we trying to achieve the WFE and application server separation we used to do in N-Tier deployments. (to be honest I winked a little bit here when thinking of microservices)
Layering Internal Services
WFE services will route the requests to the internal services with the specific service resolution. Communication from WFE services to the internal services are generally based on HTTP because this provides loose coupling between the WFE services and internal services.
First let’s see what should happen when WFE wants to route a request to the internal services.
- WFE should resolve the service location – either via Naming Service directly or via the SF Reverse Proxy
- Services should have unique URLs (apart from the IP and port) because when services move from node to node, one service can pick the same port from a node which was used by the previous service and could cause issues. – In such cases a connection can be made to a wrong service (read more from this link)
Rule #3: It is recommended to use SF Reverse Proxy for internal HTTP service communications, because it provides features like endpoint resolution, connection retry, failure resolution and etc.
Reverse Proxy should be enabled in the cluster with the HttpApplicationGatewayEndpoint tag in ClusterManifest.xml. The default port for reverse proxy is 19801 and this service run in all the nodes. You can customize this via ClusterManifest.xml
WFE services should resolve the internal services (first layer services which has HTTP communication from WFE services) using SF Reverse Proxy.
http://localhost:19801/ApplicationName/InternalServiceName/RestOfTheUri
The localhost is applicable as the request is sent via the Reverse Proxy agent running on the node which is calling the internal service. The above URL will be used in a simple HTTPClient implementation to make the call. The below snippet shows a simple GET request.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| string reverseProxyUrl = "http://localhost:19801/ApplicationName/InternalServiceName/RestOfTheUri"; | |
| var httpClient = new HttpClient(); | |
| var response = await httpClient.GetAsync(reverseProxyUrl); |
Things to be noted in SF Reverse Proxy
The above URL is the simplest form for a reverse proxy URL which resolves a stateless services. Since This article assumes the 1st layer internal services are stateless the above URL structure will work – no need to mentioned the partition id and kind. In order to learn the full URI structure read this link
Reverse Proxy does retries when a service is failed or not found. Not found can happen when a service is moved from the requested node. Not Found can also occur when your internal service APIs return 404 for a not found business entity. Reverse Proxy requires a way to distinguish between these two cases because if it’s a business logic which returns 404 then there’s no point retrying. This scenario is explained in above article. In order to avoid a wrong service being called internal stateless services should be have unique service URL integration.
In order to mitigate this, internal services should tell the Reverse Proxy not to retry with the header value. You can do this with an IResultFilter implementation like below and apply the attribute to your controllers. So any action method returns 404 (business service aware 404) values will have this header and Reverse Proxy will understand the situation.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public class ReverseProxyServiceResponseFilter : IResultFilter | |
| { | |
| public void OnResultExecuted(ResultExecutedContext context) | |
| { | |
| if(context.HttpContext.Response.StatusCode == 404) | |
| { | |
| context.HttpContext.Response.Headers.Add("X-ServiceFabric", "ResourceNotFound"); | |
| } | |
| } | |
| public void OnResultExecuting(ResultExecutingContext context) | |
| { | |
| } | |
| } |
So in this mode the internal stateless services which uses HTTP endpoints should have following aspects
- Dynamic port assignment
- Kestrel Service listener
- Can scale the service instance as long as FD:UD constraints are not violated
- No restrictions in dev enviornment
- ServiceFabricIntegrationOption set to UseUniqueServiceUrl
Note: User revers proxy for internal HTTP communication. Clients outside the cluster SHOULD connect to the WFEs via LB or any such similar service. Mapping Reverse Proxy to the LB can cause the clients outside the cluster to reach the HTTP service endpoints which are not supposed to be discoverable outside the cluster.
Summary
Let me summarize the items in points below.
- Use Kestrel for WFE with static port assignment with placement strategies for the nodes allocated to handle WFE workload.
- Using HttpSys for WFE is fine, but do not use this in the intention of scaling out thus would not yield the right expected result.
- Use Kestrel for internal HTTP stateless services with dynamic port allocation and enabling unique service URL.
- Use SF Reverse Proxy for internal HTTP communications whenever possible
- It is not recommended to map the SF Reverse Proxy the external LB or Gateway service.
In the endpoint configuration services have endpoint type which can be set to Input or Internal. I did some testing but failed as both types exposes the services as long as they have a valid port mapping to LB. Finally ended up asking from the creators and this is the answer I got. So technically endpoint type does not matter.
