Introduction
Microservices is here to stay and we can witness the increasing popularity and the maturing technology stack which facilitate microservices. In this great article which explains about the maturity of microservices and the 2.0 stack, it mentions three key aspects.
- Service mesh
- Matured orchestrators
- RPC based service protocols.
This post focuses on the communication infrastructure in Service Fabric. Service Mesh is about the communication infrastructure in a microservices / distributed system platform.
First, let’s look at What is a service mesh ? In the simplest explanation, service mesh is all about service to service communication. Say, service A wants to talk to service B, then Service A should have all the network and communication functionality and the corresponding implementations, in addition to its business logic. Implementation of the the network functionality makes the service development complex and unnecessarily big.
Service mesh abstracts all or the majority of the networking and communications functionality from a service by providing a communication infrastructure, allowing the services to remain clean with their own business logic.
So with that high level understanding if we do some googling and summarize the results, we will have a definition of a service mesh, with these two key attributes.
- Service mesh is a network infrastructure layer
- Primary (or the sole) purpose is to facilitate the service to service communication in cloud native applications.
Cloud native ?? – (wink) do not bother much on that, for the sake of this article, it is safe to assume a distributed system’s service communication.
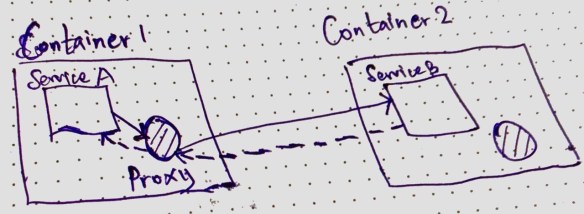
Modern service mesh implementations are proxies which run as sidecar for the services. Generally an agent runs on each node and the services run on the node talk to the proxy and proxy does the service resolution and perform communication.
When Service A wants to talk to Service B
- When service A calls its local proxy with the request.
- The local proxy perform service resolution and makes the request to Service B
- Service B replies to the proxy running in Container 1
- Service A receives the response from its local proxy
- Service B’s local proxy is NOT used in this communication. Only the caller needs a proxy not the respondent.
- Service A is NOT aware of service resolution, resiliency and other network functionalities required to make this call.
There are notable service mesh implementations in the market, Linkered and Istio are quite famous and Conduit is another one and many more in the market. This is a good article explaining those different service mesh technologies.
The mentioned service mesh implementations are known in the Kubernetes and Docker based microservices, but what about service mesh in Service Fabric.
Service mesh is inherent in Service Fabric
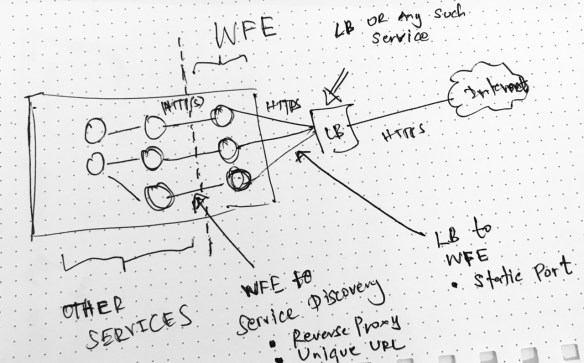
Service Fabric has a proxy based communication system. Defining this as a service mesh is up to the agreed definition of service mesh. Typically there should be a control plane and data plane in a service mesh implementation. Before diving into the details of it, let’s see the available proxy based communication setup in Service Fabric.
Reverse Proxy for HTTP Communication
SF has a Reverse Proxy implementation for HTTP communications. This proxy runs an agent in each node when enabled. This reverse proxy handles the service discovery and resiliency in HTTP based service to service communication. If you want to read more practical aspect of the Reverse Proxy implementation, this article explains the service communication and SF reverse proxy implementation.
Reverse Proxy by default runs on port 19081 and can be configured in the clusterManifest.json
{
............
"reverseProxyEndpointPort": "19081"
............
}
In the local development machine this is configured in the clusterManifest.xml
<HttpApplicationGatewayEndpoint Port="19081" Protocol="http" />
When Service A wants to call the Service B’s APIs, it calls its local reverse proxy with a following URL structure.
http://localhost:{port}/{application name}/{service name}/{api action path}
There are many variations of reverse proxy URLs should be used depending what kind of a service the calls are made. This is a detailed article about Service Fabric Reverse Proxy.
RPC Communication in Service Fabric
RPC Communications in Service Fabric are facilitated by the Service Fabric Remoting SDK. The SDK has the following ServiceProxy class.
Microsoft.ServiceFabric.Services.Remoting.Client.ServiceProxyService Proxy class creates a lightweight local proxy for RPC communication and provided by the factory implementation in the SDK. Since we use the SDK to create the RPC proxy, in contrast to the HTTP reverse proxy this has the application defined lifespan and there’s no agent runs in each node.
Regardless of the implementation both the HTTP and RPC communication are well supported by Service Fabric by native and has the sidecar based proxy model implementation.
Data Plane and Control Plane in Service Fabric
From the web inferred definition of service mesh, it has two key components, (note, now we’re talking the details of service mesh) known as data plane and control plane. I recommend to read this article which explains the data plane and the control plane in service mesh.
The inbuilt sidecar based communication proxies in Service Fabric form the network communication infrastructure : which represents the data plane component of the service mesh. The sidecar proxies in Service Fabric form the data plane.
Control plane is generally bit confusing to understand, but in short, it is safe to assume control plane has the policies to manage and orchestrate the data plane of the service mesh.
In Service Fabric, control plane is not available as per the complete definition in the above article. Most of the control plane functions are application model specific and implemented by the developers and some are in built in the communication and federation subsystem of Service Fabric. The key missing piece in the control plane component of Service Fabric is, the unified UI to manage the communication infrastructure (or the data plane).
The communication infrastructure cannot be managed separate to the application infrastructure, thus a complete control plane is not available in Service Fabric.
With those observations, we can conclude:
Service Fabric’s service mesh is a sidecar proxy based network communication infrastructure, which is leaning much on the data plane attributes of a service mesh.