This article focuses on the steps on how to configure the Always Encrypted (AE) feature for SQL Databases using Azure Key Vault as the key store provider; which is still in preview at the time of this writing.
In order to try out what I have explained here you should have January 2016 preview or upper version of SSMS.
You can download the January 2016 preview version here
Please note this is not an article to discuss about what AE is and how it works nor an introduction to Azure Key Vault. I recommend to read these following posts before continuing this article in order to get the full understanding.
Settings up Always Encrypted in SQL Database using Azure Key Vault
In order to set up the Always Encrypted, first we need to create Column Master Key (CMK) and Column Encryption Key (CEK).
Creating CMK.
Navigate to the SQL Databases using SSMS. Expand the database node and then expand the Security section. Under the Security section you will see Always Encrypted Keys node. Right click on that and you will see the menu, shown in the below image.

Select ‘New Column Master Key’ and you will get the below dialog box. Name your CMK (cmk1) and then select the Azure Key Vault as Key Store. Click the Sign In button to login to Azure subscription.

You should use an Azure account with at least co-admin privileges to the Azure subscription where the Azure Key Vault is. After signing in you will see the list of Azure Key Vaults in the drop down, choose the one you want to use as KMS for the CMK.

Click Generate Key and let the Azure Key Vault generate a key for you. This will be your CMK.
Creating CEK.
As shown in the below image right click on the ‘Column Encryption Keys’ node and create a CEK.

You will get a dialog box shown below. Name the CEK and choose the CMK created above. 
When you select the CMK stored Azure Key Vault, you will see the Azure login dialog. Here you should enter the credentials of the user who has permission to access the particular key in the vault. If not you will get an error analogous to the below dialog.

In order to give the permission to the key from to the specific user, execute the following PowerShell script.
![]()
Note: When you create the CMK you login to Azure using a co-admin credential who has access to Vault, but that does not make him/her able to manage the keys created. So using the same credentials when creating the CEK might produce the above error. You should give permissions to the user account which is used to access the keys in the Vault.
Now the setup of creating CMK and CEK are done. Let’s create a table.
Execute this script in order to create the table in the database. (click on the images to enlarge)

We have created a table with 3 columns 2 of them are encrypted using CEK1 with Always Encrypted Feature. This completes the setup in the SQL Database.
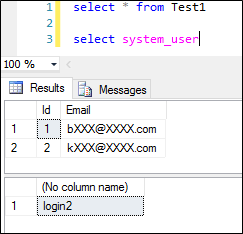
You can query the database for more information about the Always Encrypted settings. You will find some useful queries in this article.
Application Setup
We are done with all the setups in the SQL Databases, in order to work with the Always Encrypted feature enabled database we need a .NET 4.6 application.
Also since we use Azure Key Vault as the key store provider, we need to implement a custom provider, this could be done by implementing the SqlColumnEncryptionKeyStoreProvider abstract class in System.Data.SqlClient.
You can find an implementation here.
Below is the core code snippets of the implementation.

The connection settings goes like below.

Implementing the GetToken method
Only AAD identities can access Azure Key Vault, so now our application needs an AAD identity in order to communicate with the Azure Key Vault.
So we need an AAD application which has permissions to the Azure Key Vault in order to access Azure Key Vault programmatically.
Create an AAD app and the App Id and the App secret key.
And the set the permission for the app in the Key Vault in using PowerShell.

So the GetToken method goes as below.

In the above snippet the provider name is AZURE_KEY_VAULT, you can retrieve this information by executing the following TSQL command.

After all the setups the application and the database both are ready with Always Encrypted enabled with Azure Key Vault.