Modern applications communicate with many external services; these external services could be from third party providers or from the same provider or they are components of the same application. Micro service architecture is a great example for disconnected, individually managed and scalable software components that work together. The communication takes place using simple HTTP endpoints.
Example: Think that you’re developing a modern shopping cart. Product catalog could be one micro service, ordering component would be another one and the user comment and feedback system would be another one. All three services together provide the full shopping cart experience.
Each service is built to be consumed by each other, they might have sophisticated API Management interfaces or just a simple self-documented REST endpoints or undocumented REST endpoints.
Another example is Facebook, it has messenger feature implemented by a totally different team from who manage the feeds page and the Edge Ranking stuff. Each team push updates and individually manage and operate. The entire Facebook experience comes from the whole collection of micro services.
So the communication among these components is essential. Circuit Breaker (CB) manages the communication by acting as a proxy. If a service is down, then no point trying it and wasting the time. If a service is being recovered, then better not to congest it with flooded requests; time to heal should be given to the service.
Circuit Breaker and Retry Logics
It is important to understand when to use Circuit Breaker and when to retry. In case of transient failures, application should retry. Transient failures are temporary failures; a common example would be TimeOutException. It is obvious that we can retry for one more time.
But think an API Management gateway blocks your call for some reason (IP restriction, Request Limit) or any 500 error then you should stop the retry and inform the caller about the issue. And let the service heal. This is where Circuit Breaker helps.
How Circuit Breaker Works?
Circuit Breaker has 3 states.
- Closed
- Open
- Partially Open
Look at the below diagram and follow the context for the explanation.

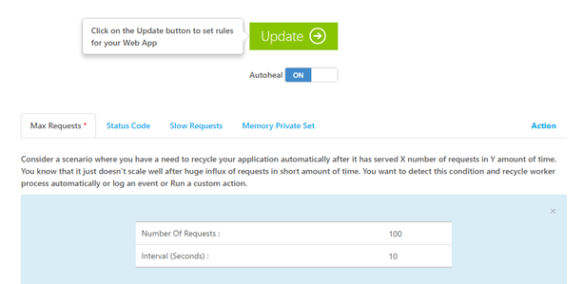
By default, Circuit Breaker is in the Closed state. The first request comes in and it will be routed to the externa service. Circuit Breaker keeps a counter for the non-transient failures occur in the external service in a given time period. Say that the given time period is 15 seconds and the failure threshold is 10, if the service fails 10 times within 15 seconds for n number of requests then Circuit Breaker goes to Open state. If there’re no or less than 10 failures during 15 seconds, the failure counter will be reset and Circuit Breaker remains in Closed state.
In the Open state, Circuit Breaker does not forward any requests to the external service, regardless of how many requests it receives. It replies to those requests with the last known exception. It remains in the Open state for a specified time period. After the Open state has elapsed Circuit Breaker enters the Partial Open state / Semi Open State.
In the Partial Open state, some of the requests are being forwarded to the external service while others are being rejected as Circuit Breaker is in Open State. In the allowed number of requests Circuit Breaker monitors the success of those calls, and if a specified number of calls are continuously successful then Circuit Breaker resets it counters and goes to the Closed state.
The mechanism of which calls should reach the service during the Partial Open state is up to the implementation. You can simply write an algorithm to reject one call after the other or you can use your own business domain. Example calls from members of Admin role can pass through and others fail.
Partial Open State and preventing Senseless blocking.
This is a bit tricky state because, this state does not have a timeout period. So Circuit Breaker will remain in the Partial Open state until the right number of requests come to satisfy the condition. This might not be preferable in some cases.
Example, consider the service is down at 10:00:00AM and Circuit Breaker goes to Open state. After 3 minutes (at 10:03:00AM) it goes to Partial Open state. From 10:03:00AM to 10:23:00AM only few requests came and some of them will be rejected by the Circuit Breaker, and still Circuit Breaker is waiting for more calls though the service is perfectly back to normal by 10:08:00AM. I named this kind of prevention from the Circuit Breaker as Senseless Blocking.
There are few remedies you can implement to prevent senseless blocking. Simply we can put a timeout period for the Partial Open state or we can do a heartbeat check from the circuit breaker to the external service using a background thread. But be mindful that senseless blocking is an issue in Circuit Breaker pattern.
When not to use Circuit Breaker?
When you do not make frequent calls to the external service, it is better to do it without going through a Circuit Breaker, because when your calls are not frequent there’s a high probability that you might face senseless blocking.
Implementation
I have provided a reusable pattern template for the Circuit Breaker.
Code is available in GitHub : https://github.com/thuru/CloudPatterns/tree/master/CloudPatterns/CircuitBreakerPattern