
Introduction
First let me begin with ‘What is meant by Shadow IT ?’. In a broader view shadow IT is, any sort of IT usage without the direct governance of IT department of your organization.
Sometimes this remains as a violation of the company policies, but the proliferation of the cloud SaaS applications and BYOD trends makes shadow IT an unavoidable practice.

A simple example would be a cloud based file sharing application used in an organization which is not officially approved by the IT.
In most cases organizations are not aware of the tools used by their employees and shadow IT usage. Only 8% of the organizations are aware of their shadow IT usage.
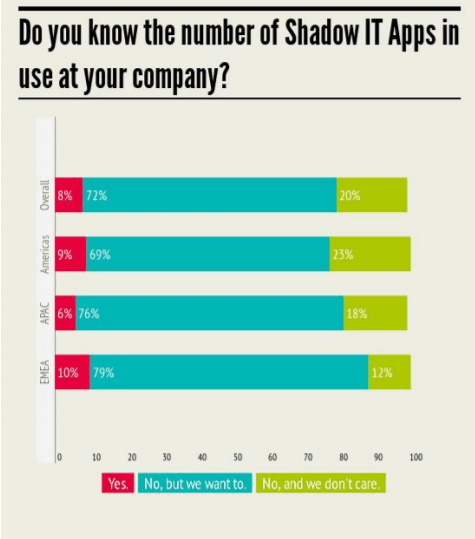
Taken from – Cloud Adoption Practices & Priorities report 2015 : Cloud Security Alliance.
In my opinion there are two major reasons which fuel the increasing shadow IT practices. First, when employees have higher and diversified devices than the ones available at work. Secondly when they find sophisticated SaaS tools than the ones available at work.
Another notable reason is – communication between contextual boundaries, like departments, SBUs and other companies – people tend to use cloud based SaaS tools either for convenience or due to some already existing shadow IT practices of a party.
How to with AAD V2
So, what is the importance in software development in shadow IT ? – One of the projects I’m involved with has been going through the transformation of being an internal system to a public system. We decided to open this up as a SaaS tool that anyone with a Azure Active Directory (AAD) credential can use it.
Behind the scenes the application has rules to track the user, tenant, recurrence of the tenant, other users in the tenant and the list grows. But anyone with a valid AAD account can simply create an account and start using it. This makes the application a perfectly fitted candidate in Shadow IT. It’s a perfect Shadow IT tool.
As SaaS provider we want many users as possible using our system, after all we charge per transaction 🙂
- The application is registered as a AAD V2 app in the home directory.
- We removed the friction in the enrollment by keeping only the minimal delegated permission (User.Read) in the app.
But in order to provide more sophisticated experience inside the application we require access to AAD and read permissions on other users. In order obtain this we thought of an approved shadow IT practice via application permissions.
- We added the admin privileges to the application permissions, and generated application secrets.
The configured AAD V2 app principle look similar to the below one.
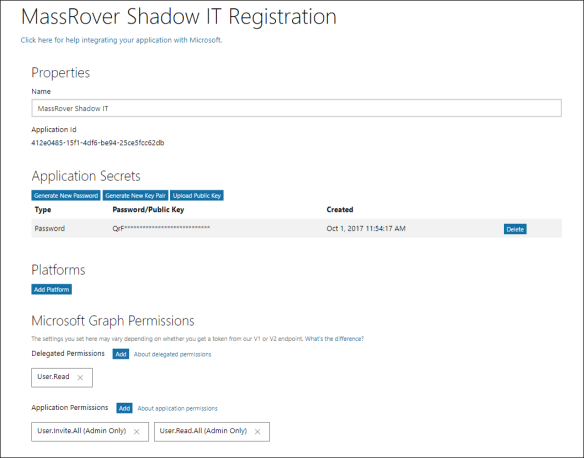
In the experience point of view, we trigger the typical following normal AAD login URL for the user login. We trigger the organization endpoint (restrict the Microsoft accounts) with the following URL. (You can try the URL)
https://login.microsoftonline.com/organizations/oauth2/v2.0/authorize?client_id=412e0485-15f1-4df6-be94-25ce5fcc62db&response_type=id_token&redirect_uri=https://localhost:8080&scope=user.read openid profile&nonce=3c9d2ab9-2d3b-4
This will popup the login and after the successful validation of the credentials you’ll see the following consent screen.

User accepts the consent and she’s inside the SaaS application Shadow IT begins here. In order to get the additional rights we allow the user to inform her IT administrator and ask for additional permission.
IT administrator will be notified by the email entered by the user with following admin consent link.
http s://login.microsoftonline.com/[tenantid]/adminconsent?client_id=412e0485-15f1-4df6-be94-25ce5fcc62db&response_type=id_toke&redirect_uri=https://localhost:8080
Here we obtain the tenant id from the id_token from the user logged in previous step. When the IT administrator who has admin rights in the AAD hits the above URL and after successful validation of the credentials he will see the following admin consent screen.

The permission list varies based on the configured application permissions in the application. After successful consent grant, the redirection will happen to a URL similar like this
http s://localhost:8080/?admin_consent=True&tenant=[tenant id]
Now the application can use the app secret to access the specific tenant.
Note: From AAD principle point of view, the service principle of the application is registered in the tenant in the first step. (This configuration should be allowed in AAD – by default this is enabled) and during the admin consent process the service principle gets more permissions granted to it.
Summary
We achieved both the frictionless experience for the user and allowing administrator to grant the permission when required. The below image summarizes the process.

- By request IT admin knows the usage of application and it give some light to the usage of such SaaS.
- By granting access IT admin allows it to the organizational use and removing shadow IT context.
- If admin rejects the consent the organizational user knows that he’s in Shadow IT context.
- Blocking of such SaaS may continue based on the organizational policies.










