In the recent times, I have been working on building a product for a ‘pure startup’. What I meant by ‘pure startup’ is not about how novel the concept is, but development of the product needs to be started from the ground zero.
This scenario often includes the technical stakeholders to take part in the the product features and feature release plans. The technical stakeholders share and believe (to some extent) the vision of the entrepreneur.
Generally my role is to facilitate this process from the technical point of view, whilst aiding the entrepreneur reach his goals with his product.
Technical stakeholders tend to put all the great new stuff and deliver the product for a billion dollar business; entrepreneurs often occupied by the big dream of the product and can easily be mislead from the business goals.
The argument is not about not using great technologies and all the buzzwords, but the argument mostly comes – what we require at which stage, how big the idea is, how fast it can grow to hit the first million users, would the current architecture supports it and etc.
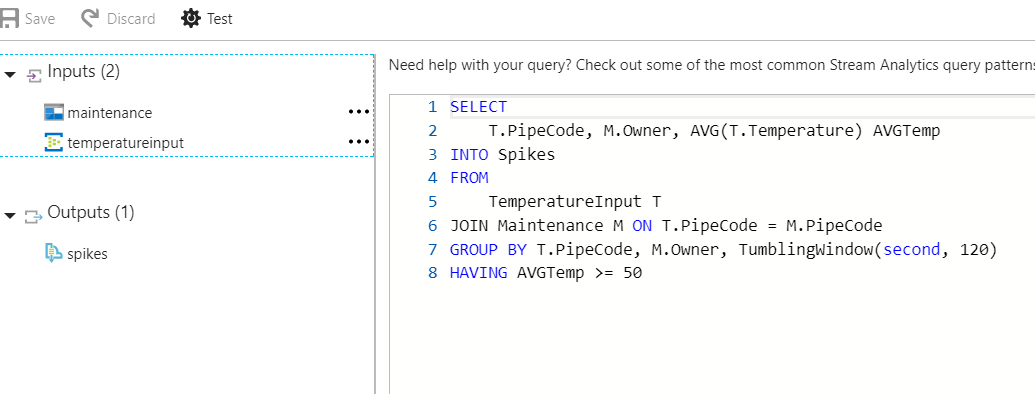
The confusion was from a real experience, that one of the recent startups wanted to go with one of the big cluster management / micro services platform in Azure for a relatively simple operational business.
Technical stakeholders of the project felt that, the micro services approach is not required at the beginning, and suggested the simple solution. The first question popped from the business stakeholders is – “Fine, but how much effort is required to go for micro services model at a later stage if it’s required?”
The answer is simple “WE DON’T KNOW, but we’ll guide you on any technology issues you face in the product and make sure it works” – That’s the commitment and that’s the way things work.
That does not mean that we shouldn’t not start with complex architecture and cumbersome technologies, there’s always a balance and at the core we should discover what is right for the business. In order to help this decision I coined the term Cost Effective Architecture.
As businesses grow and change, the agility in the technology and the chosen platform becomes quintessential. Moving the business forward with the right technological decisions for the existing context, whilst considering the future change in a cost-effective manner is the core idea of Cost Effective Architecture (CEA).
Let’s categorize the businesses under two categories based on the target users.
1. Internal systems – The user base is known before the enrollment. Multi-tenant systems where a tenant can be an organization or department or any such group. The probability of the sudden usage spikes and user base expansion is highly unlikely. We can call them as tenant based products as well, but they are not necessarily the tenant based. Intranet systems automatically falls under this category (I wonder is there anyone developing Intranet solutions now). Good examples are Office 365, Salesforce and etc.
2. Public systems – Targeted for general public, user enrollment is not known before the enrollment. Mostly these are user based systems, the concept tenants rarely observed. The probability of the sudden usage spikes and user base expansion is expected based on the business model. Any public content applications fall under this category. Good examples are Spotify, LinkedIn and etc.
Another main categorization of the products based on the current user base.
1. Existing systems – These are the systems which already have gone production and have decent battle time in the live environment. Usage patterns and loads are fairly predictable.
2. Startup systems – These are either not launched or not developed. They can have a solid business model/requirement or they simply some great evolving ideas from entrepreneurs.
These two different categorizations leave us, with the following 2×2 model.

Business Categorization of CEA
C1 – Internal systems with existing users. Internal systems can be more complex than some public systems, because they can have large number of users and many integrations with legacy and non legacy systems. The development changes occur due to technology invalidation, cost of maintenance, new feature requirements or scale out/up limitations of the predicted usage.
Since the new user enrollment is mostly predictable and the existing usage of the systems are well known, design and technology decisions have the luxury to have in depth comparison and analysis. These systems often have the bulkiness with them to move, as this is another reason for the slow development. Often collateral systems are developed (APIs, mobile apps) around the C1 systems and core solution of the C1 would move slowly towards the change.
C2 – These are public systems with existing users, the usage is somewhat known but unpredictable. Development of new features and changes are frequent. Technology decisions are based on the principle of keeping enough headroom for next wave of the new active users, thus abundance of the computing resources is justifiable as long as the growth is predictable. Downtime is critical since these are public systems. Agility and DevOps are key existence factors.
C3 – Internal startup systems. Go to market or launch is a critical factor. More often the development of these systems begin with a fixed number of promised user base. Business model is validated through implementations. Since these are internal systems usage spikes are unlikely, but that should not influence to bad technology selection. Sub systems are somewhat understood and discovered.
C4 – Systems with the intention to reach market with possible business cases. Mostly a hyper spike is not expected and validation of the market adaptability and usage needs to be discovered. Mission critical infrastructure or advanced design decisions can be put on hold in order to save time and money. It does not mean to implement bad practices but initiating the development in a way that can be scaled to larger scenarios with significantly less effort. In the cloud PaaS offerings helps to gain this. Primary focus is go to market as soon as possible.
Note :
Though CEA has the above categorizations, it does not force the ideas under a specific category just because a business requirement or case is theoretically mapped to those scenarios. Example – A novel idea can directly be considered under C2 rather being in C4, from the very first day of the system design and development, as long as the user base and market anticipation is clear and well understood. Systems can be started with costly reliable mission critical infrastructure and major design decisions and strategies can be considered upfront in such cases.