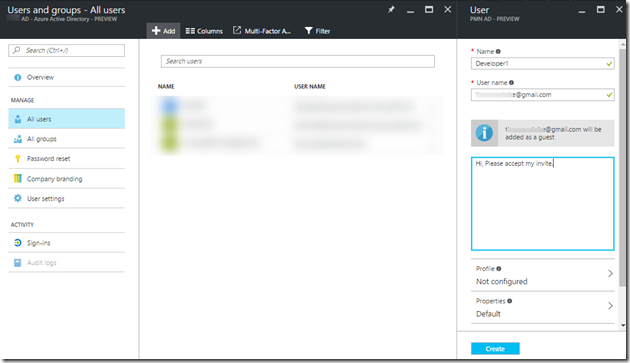
Multi tenancy is a popular buzzword, often heard coupled along with cloud computing terminology. This is the issue and has created a dogma and some believe that multi tenancy can only be related with the cloud and cloud based SaaS services.
Based on the definition from Wikipedia
The term “software multitenancy” refers to a software architecture in which a single instance of software runs on a server and serves multiple tenants. A tenant is a group of users who share a common access with specific privileges to the software instance….
The core concern is – Pragmatically it is hard to define what a single software instance is ?
If multi tenancy is all about handling group of users (as tenants) we’ve been doing that with our good old, role based software systems, that’s not something new.
If we consider about the single instance of a software system, then there are confusions on how to consider the scale out scenarios and replications. (do not forget the DR plans with read access). In the software instances there could be confusions in the granular levels of programmatic constructs as well, like – are we talking about application level mutexes or object level singletons.
Handling different group of users in a software is very common scenario. We see this problem in different layers of a software solution – in terms of data partitioning, security, noisy neighbor issues and much more.
But taking a SaaS solution and pointing the whole as a multi-tenant or non multi-tenant solution is technically wrong, though it has some conceptual truth in it.
In particular it becomes really annoying when someone tells that cloud supports multi tenancy and moving to cloud will give the ability to support multiple tenants.
Let’s see how things get complicated, consider a simple scenario where organizations (for the ease of understanding the tenants) can upload and convert videos to desired formats and stream them online. Look at the below diagram in a simple overview. (note – the connections and directions do not reflect any and only data flow)

Here, the WFE is a web application and runs in single web server (multi tenant ?), and the service layer is running on two machines with the load balancer. (multi tenant ? or not) Web application access the cache which is a single instance serving as a common cache for all tenants. (multi tenant ?) Messaging Queue, storage and transcoding services also runs single instances (multi-tenant ?) Each tenant has a different dedicated database (single tenant ?).
So in the entire system each layer or the software infrastructure has its own number of instances – so it’s almost impossible to call an entire system as multi tenant in technical perspective.
As a business unit, the system supports group of users (organizations in the above example) and regardless of the cloud or not, it is a multi tenant system.
Hope this will clear the misunderstanding of believing or arguing a SaaS is a multi tenant or just because moving a solution to cloud would make it multi tenant.