Introduction
Sometime back when it was in the preview, I posted an article on Azure Managed Service Identity (MSI) and how we can use it, to eliminate storing credentials in the code, whilst avoiding the bootstrap problem. Read the link for more details.
This post is about Managed Identity, in short, Managed Identity is the new name for Managed Service Identity. Though the purpose and the functionality stay the same, Managed Identities provide more granular control, Azure Portal options and sophisticated improved SDK support, which convinced me enough to write a post.
Managed Identities is a feature of Azure Active Directory (free to use), which helps to eliminate storing credentials in the code. Since, Managed Identities is a feature of AAD, it can be used to authenticate to any Azure service that supports AAD authentication. Let’s start from AAD and drill down into the Managed Identities.
AAD Principles
AAD can have two different principles, user principle and service principle. A user principle is a user object, and a service principle is an instance of application registration.

So what is an application in AAD ? An application is a global template for a service principle. The directory (AAD tenant), the application is registered is known as the home directory. When the permissions / consent has been given to a application the service principle object is created.
Other than the creation and configuration phases, what we deal with is a service principle. I recommend you to use the terms user principle, service principle and application to have the clear understanding in the communication. You can read more about the application and service principle from this link
Managed Identities
Managed Identities are special type of service principles, they are two types.
User assigned Managed Identity – Available to create as a standalone Azure resource. Should be created manually, when created, a corresponding AAD application will be registered (more details below). One Azure resource can have many user assigned managed identities. The life cycle of a user assigned managed identity is independent of the resource life cycle, meaning a user assigned managed identity can exist without being attached to any resource.
System assigned Managed Identity – These are created by Azure when enabling the Managed Identity for a service. The lifetime is scoped to the lifetime of the resource. One service can have only one system assigned Managed Identity.
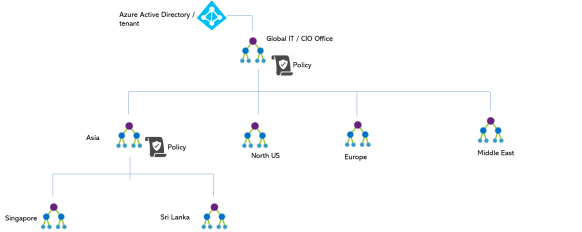
The below image summarizes the things. Mindful this, is a specific diagram I have created to illustrate the AAD principles. AAD is not limited to below context.

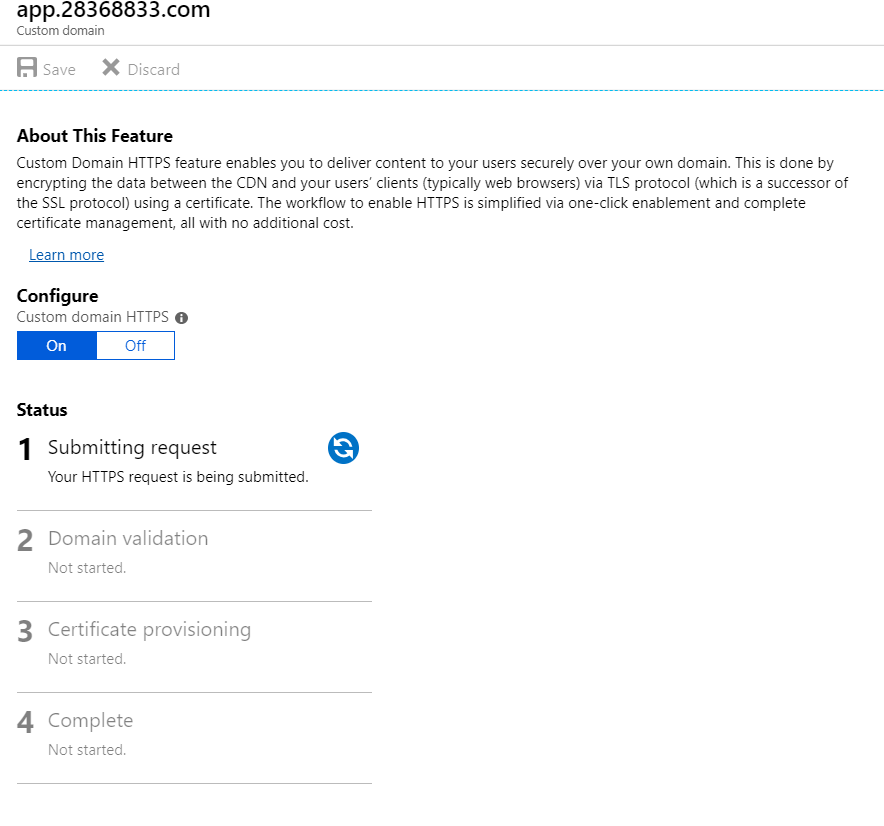
Enabling Managed Identities to a Service (App Service)
I take a simple example of how we can use Managed Identities to access a Azure Key Vault, which contains the secrets. This article covers creation and assignment of the Managed Identities to App Service, —

System Assigned Identity, we have to enable and in the second tab, you can see the User Assigned identity (still in preview).
Enabling System Assigned Managed Identity
Switch the status to ON and this will create a system assigned managed identity. Just to explain what is happening behind the scenes.
Before enabling run this PowerShell command (you need GA permissions to the tenant) to see the number of service principles in the AAD.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| (Get-AzureRmADServicePrincipal).Count |
This will give you the number of service principles in the AAD, and after enabling the System Assigned Managed Identity when you run the above command the count will be +1. Also in the portal, you can see the object id of the service principle.

Executing the below will give the details
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Get-AzureRmADServicePrincipal -ObjectId db9c6f9e-bea0-4325-b18c-dcd6eda668af | |
| ServicePrincipalNames : {98b1ebaf-b6b2-4368-ba53-c36ae0551b90, https://identity.azure.net/4zuSVB9vvyfEk5wvTupj9aFQnGVY0bvqMPfQ9bTKrwk=} | |
| ApplicationId : 98b1ebaf-b6b2-4368-ba53-c36ae0551b90 | |
| DisplayName : chimp01 | |
| Id : db9c6f9e-bea0-4325-b18c-dcd6eda668af | |
| Type : ServicePrincipal |
Behind the scenes, Azure has created a service principle for us. In the portal, under Enterprise Applications, make a search with the Display Name (retrieved from PowerShell), you will see the associated service principle. (make sure, you have selected All Applications in the drop down)
But, this is a special kind of a service principle, which we cannot configure any explicit permissions. If you navigate to the Permissions section you will notice that.
Enabling User Assigned Managed Identity
This is still in preview, and in the second tab of the Identity blade. Here we add a Managed Identity as a standalone resource in Azure. You can add an existing user assigned Managed Identity in the tab as shown below.
Screen Link 001

In order to create a User Assigned Managed Identity, you can add it in the portal, as a separate resource. Search for User Assigned Managed Identity, and click create.

This is like any other Azure resource creation, fill the details and create it.

After creating the User Assigned Managed Identity, run the above count script, you will see one more service principle in AAD tenant.
Also, if you search the resource name under the Enterprise Applications (All Applications enabled) you will see the service principle.
Additionally, we can see the created Managed Identity as a resource in the specified Resource Group.

Now go back to the screen link 001, and you can add the created user assigned Managed Identity.

As you can see, we can add more than one user assigned managed identities to a Azure service.
Continuation
We have created and assigned the Managed Identities to our service, next article will explain how to use them both in production and development.