Cloud computing has proven its ability, to be the baseline element of digital transformation. Out of different the cloud delivery models public, private and hybrid, public cloud plays a significant role in digital transformation across all the industries, enabling the businesses to deliver and innovate at speed.
Many enterprises start their cloud journey with IaaS with pure lift & shift, but beyond the IaaS, PaaS and modern e-PaaS famously known as Serverless bring the real value of the cloud to the businesses. PaaS and Serverless bring ease of management & maintenance, achieving scale & agility, adopting modern tech stack with the increasing speed, leveraging complex technologies like Machine Learning and Blockchain available as services and many more.
Due to those reasons, most organizations favor PaaS and Serverless over IaaS. We see increasing interest in PaaS and Serverless not only from SMEs but also from large enterprises.
PaaS services are highly competitive in public cloud. Public cloud platforms/vendors notably Azure & AWS, compete with each other, offering numerous PaaS services. PaaS and Serverless services are either hard or impossible to have them in on-premise environments with the same flexibility and scale as in public cloud. This has not only made PaaS services a unique selling point of public cloud, but also making them quite native to respective cloud platforms.
This leaves the PaaS and Serverless context, analogous a conceptual level, but they differ significantly at the implementation level. Developers should know the details of the chosen cloud platform, in order to fully leverage the features the platform offers.
“Practical Azure Application Development” addresses two key challenges of PaaS and Serverless solution design & development on Azure.
Provides comprehensive technology decision making guide and details of Azure PaaS and Serverless services, and helps in deciding the right service for the problem in hand.
A step by step approach on how to implement the selected services with a real world sample solution, starting from designing, to development, deployment and post deployment monitoring.
You can find ample amount of content in the web explaining the usage of different services of Azure. But most of them are focused on one particular service and explaining the technical details of a single service.
That is good information in knowing individual services as individual building blocks,
but in reality, what most important is, knowing how to build an end to end solution on a cloud PaaS stack, integrating different native services knowing their nuances.
“Practical Azure Application Development” takes you in a journey starting from explaining what is cloud computing and how to procure an Azure account to developing a document management solution using different Azure services.
It includes
How to procure an Azure account.
Integration with Visual Studio Team Services and implementing continuous integration and automated deployments.
Managing ARM templates and auto provisioning environments.
Developing and deploying applications to Azure App Service.
Persistence using SQL Database and Azure Storage.
Expanding the solution with Cosmos DB.
Performance tuning with Redis Cache.
Integration with Azure Active Directory (AAD) and multi-tenancy concepts.
Managing security and permissions using Azure RBAC.
Creating and delivering reports with Azure Power BI Embedded
The approach and the coverage of the content of the book has made it one of the all times best about Azure, rated by Book Authority.
Planning the service communication and the cluster setup is one of the important items we should do when developing on Service Fabric (SF). In this article I have tried my best to stick to the minimalist options in setting up the cluster whilst sufficient details by eliminating the common doubts. The motive behind this research is to find the optimum cluster with little amount of development and ops time.
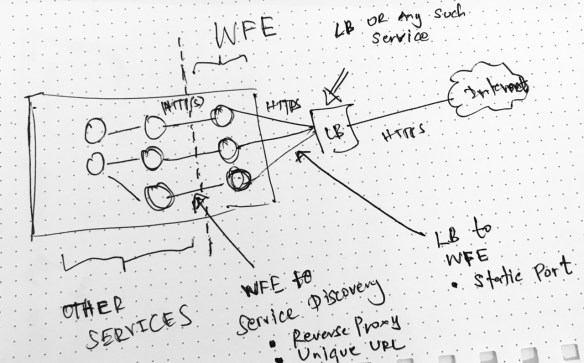
Layering WFE Services
Rule #1 : It is not recommended to open the services to the Internet. You would use a either a Load Balancer (LB) or a Gateway service. In on-prem implementations mostly this would be a LB and your cluster will reside behind a firewall.
The services mapped or connected to the LB act as the Web Front End (WFE) services. In most cases these are stateless services .
Rule #2 : LB needs to find the WFE services so WFE services should have static ports. LB (based on the selection) will have a direct or configured port mapping to these WFE services.
When you create a ASP.NET Core stateless service, Visual Studio (VS) will create the service with following aspects.
VS will assign a static port to the service.
Service Instance is set to 1 in in both Local.1Node.xml and Local.5Node.xml.
Service Instance is -1 in Cloud.xml
Kestrel Service listener
ServiceFabricIntegrationOption set to None
Since Kestrel does not support port sharing, in the local development environment the Kestrel based stateless services are set to have only one instance whenever a port has been specified.
In you development machine, if you specify an instance which results higher than 1 while a port is specified in the ServiceManifest.xml for service which Kestrel listener, then you will get the following famous SF error.
Error event: SourceId='System.FM', Property='State'.
Partition is below target replica or instance count
The above error is about, Failover Manager (FM) complaining that SF cannot create replicas as requested. In FM’s point of view, there’s a request to create more instances but due to port sharing issue in Kestrel, SF cannot create more than one instance. This is the same error you would get regardless 1 node / 5 node setup because because physically we use one machine in development.
Using HttpSys listener is an option to overcome this issue. In order to use the HttpSys listener install the following NuGet package, update the listener to HttpSysCommunicationListener and the ServiceManifest.xml as below.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
In fact, in the production deployments when more than one node available we can use Kestrel listener with static port mentioned in the ServiceManifest.xml with more than one instance. SF will place the instances in different nodes. This is why the instance count is set to -1 in Cloud.xml.
Here the -1 is safe, because setting a specific number for instance count while Kestrel is used in static port mode may create issues when the requested instance count exceeds the nodes available for SF to place the service.
Common Question: Can we use HttpSys listener and enable scaling ? This is possible but most cases specially in stateless services scaling number of instances is the typical scale out scenario. So there’s no point having a scale out strategy in a single node by congesting a node with many number of services, because running multiple instances in same the same node will not yield the desired throughput we need. Also in such cases Cluster Manager will not find enough nodes with UD/FD combination in order to place the instances and provide a warning message.
Do not make the mistake that I favor Kestrel over HttpSys in this article, there are specific cases where you need HttpSys over Kestrel. In Microsoft articles Kestrel being mentioned and most of the cases are given in such a way that Kestrel can be used to reach desired output regardless of its inability of handing port sharing. From ASP.NET Core point of view Kestrel is good as long as your service is not directly facing the Internet.
Best Practice : Do NOT place WFE services in all nodes. Have dedicated nodes for the WFE services (use placement strategies). This allows stronger separation between WFE nodes and internal nodes. We can also implement a firewall between WFE service nodes and internal service nodes. In another way we trying to achieve the WFE and application server separation we used to do in N-Tier deployments. (to be honest I winked a little bit here when thinking of microservices)
Layering Internal Services
WFE services will route the requests to the internal services with the specific service resolution. Communication from WFE services to the internal services are generally based on HTTP because this provides loose coupling between the WFE services and internal services.
First let’s see what should happen when WFE wants to route a request to the internal services.
WFE should resolve the service location – either via Naming Service directly or via the SF Reverse Proxy
Services should have unique URLs (apart from the IP and port) because when services move from node to node, one service can pick the same port from a node which was used by the previous service and could cause issues. – In such cases a connection can be made to a wrong service (read more from this link)
Rule #3: It is recommended to use SF Reverse Proxy for internal HTTP service communications, because it provides features like endpoint resolution, connection retry, failure resolution and etc.
Reverse Proxy should be enabled in the cluster with the HttpApplicationGatewayEndpoint tag in ClusterManifest.xml. The default port for reverse proxy is 19801 and this service run in all the nodes. You can customize this via ClusterManifest.xml
WFE services should resolve the internal services (first layer services which has HTTP communication from WFE services) using SF Reverse Proxy.
The localhost is applicable as the request is sent via the Reverse Proxy agent running on the node which is calling the internal service. The above URL will be used in a simple HTTPClient implementation to make the call. The below snippet shows a simple GET request.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The above URL is the simplest form for a reverse proxy URL which resolves a stateless services. Since This article assumes the 1st layer internal services are stateless the above URL structure will work – no need to mentioned the partition id and kind. In order to learn the full URI structure read this link
Reverse Proxy does retries when a service is failed or not found. Not found can happen when a service is moved from the requested node. Not Found can also occur when your internal service APIs return 404 for a not found business entity. Reverse Proxy requires a way to distinguish between these two cases because if it’s a business logic which returns 404 then there’s no point retrying. This scenario is explained in above article. In order to avoid a wrong service being called internal stateless services should be have unique service URL integration.
In order to mitigate this, internal services should tell the Reverse Proxy not to retry with the header value. You can do this with an IResultFilter implementation like below and apply the attribute to your controllers. So any action method returns 404 (business service aware 404) values will have this header and Reverse Proxy will understand the situation.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
So in this mode the internal stateless services which uses HTTP endpoints should have following aspects
Dynamic port assignment
Kestrel Service listener
Can scale the service instance as long as FD:UD constraints are not violated
No restrictions in dev enviornment
ServiceFabricIntegrationOption set to UseUniqueServiceUrl
Note: User revers proxy for internal HTTP communication. Clients outside the cluster SHOULD connect to the WFEs via LB or any such similar service. Mapping Reverse Proxy to the LB can cause the clients outside the cluster to reach the HTTP service endpoints which are not supposed to be discoverable outside the cluster.
Summary
Let me summarize the items in points below.
Use Kestrel for WFE with static port assignment with placement strategies for the nodes allocated to handle WFE workload.
Using HttpSys for WFE is fine, but do not use this in the intention of scaling out thus would not yield the right expected result.
Use Kestrel for internal HTTP stateless services with dynamic port allocation and enabling unique service URL.
Use SF Reverse Proxy for internal HTTP communications whenever possible
It is not recommended to map the SF Reverse Proxy the external LB or Gateway service.
In the endpoint configuration services have endpoint type which can be set to Input or Internal. I did some testing but failed as both types exposes the services as long as they have a valid port mapping to LB. Finally ended up asking from the creators and this is the answer I got. So technically endpoint type does not matter.
If you're referring to the endpoint type in the SF service manifest, that's a relic related to hosting SF on Cloud Services. It doesn't do anything in modern VMSS deployments. It can be omitted. Just a bit of history we can't remove or we'd break some internal partners.
Azure Cosmos Db has an impressive feature called ‘Change feed’. It enables capturing the changes in the data (inserts and updates) and provides an unified API to access those captured change events. The change event data feed can be used as an event source in the applications. You can read about the overview of this feature from this link
From an architecture point of view, the change feed feature can be used as an event sourcing mechanism. Applications can subscribe to the change event feed, By default Cosmos Db is enabled with the change feed, there are 3 different ways to subscribe to the change feed.
Azure Functions – Serverless Approach
Using Cosmos SQL SDK
Using Change Feed Processor SDK
Using Azure Functions
Setting up the change feed using Azure Functions is straight forward, this is a trigger based mechanism. We can configure a Azure Function using the portal by navigating to the Cosmos Db collection and click ‘Add Azure Function’ in the blade. This will create an Azure Function with the minimum required template to subscribe to the change feed. The below gist shows a mildly altered version of the auto generated template.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The above Function gets triggered when a change occurs in the collection (insertion of a new document or an update in the existing document). One change event trigger may contain more than one changed documents, IReadOnlyList parameter receives the list of changed documents and implements some business logic in a loop.
In order to get the feed from the last changed checkpoint, the serverless function need to persist the checkpoint information. So when we create the Azure Function, in order to capture the change, it will create a Cosmos Db document collection to store the checkpoint information. This collection is known as lease collection. The lease collection stores the continuation information per partition and helps to coordinate multiple subscribers per collection.
The below is a sample lease collection document.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
In practical implementations, we would not worry much about the lease collection structure as this is used by the Azure Function to coordinate the work and subscribe to the right change feed and right checkpoint. Serverless implementation abstracts lots of details and this is the recommended option as per the documentation from Microsoft.
Using Cosmos SQL SDK
We can use the Cosmos SQL SDK to query the change events from Cosmos Db. Use the Cosmos Db NuGet package to add the Cosmos SQL SDK.
Install-Package Microsoft.Azure.DocumentDB
This SDK provides methods to subscribe to the change feed. In this mode, developers should handle the custom checkpoint logic and persist the checkpoint data for continuation. The below gist shows a sample, which describes how to subscribe to the changes per logical partition.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The commented lines from line 31-38 shows the mechanism of subscribing at the partition key range. In my opinion, keeping the subscriptions at the logical partition level makes sense in most of the business cases, which is what shown in the above code. Logical partition name is passed as a parameter.
When the change feed is read the continuation token for the specified change feed option (partition key range or partition key) is returned by the Cosmos Db. This should be explicitly stored by the developer in order to retrieve this and resume the change feed consumption from the point where it was left.
In the code you can notice that the checkpoint information is stored against each partition.
Using Change Processor Library
Cosmos Db has a dedicated Change Processor Library, which eases up the change subscription in custom applications. This library can be used in advance subscribe scenarios as developers do not need to manage partition and continuation token logic.
Change Processor Library helps handles lots of complexity in handling the coordination of subscribers. The below gist shows the sample code for the change processor library. The change feed subscription is made per the partition range key.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
In the above code, the monitored collection and the lease collection are given and the change feed processor builder is built with the minimum required details. As a minimum requirement you should pass the IChangeFeedObserverFactory to the builder. The change feed processor library can manage rest of the things like how to share leases of different partitions between different subscribers and etc. Also, this library has features to implement custom partition processing and load balancing strategies which are not addressed here.
Summary
Cosmos Db change feed is a powerful feature to subscribe to the changes. There are three different ways to do this as mentioned above.
The below table summarizes the options and features.
I came across the term ‘Overambitious API Gateways’ from Thought Works tech radar. The point is, whether is it good or bad to have business logic in the API Gateways? Since the term Gateway is not a functional requirement and serves the purpose of a reverse proxy; it is quite obvious that including business logic in an API gateway is NOT a good design. But the idea behind the overambitious API gateways, seems to be a finger pointing at the API Gateway vendors, rather than considering the solution design and development and how the API Gateways should be used.
I prefer the term ‘Thick API Gateways‘ over overambitious API Gateways because the implementation is up to the developer regardless of what the tool can offer. This ensures an anti-pattern.
With the advent of microservices architecture, API Gateways gained another additional boost in the developer tool box, compared to other traditional integration technologies.
Microservices favor the patterns like API composer (aggregation of results from multiple services) Saga (orchestration of services with compensation) at the API Gateway. API Gateways also host other business logic like authorization, model transformation and etc. resulting a Thick API Gateway implementations.
Having said, though thick API gateway is a bad design and brings some awkward feeling at night when you sleep, in few cases it is quite inevitable. If you’re building a solution with different systems and orchestration of the business flows is easy and fast at the API gateway. In some cases it is impossible to change all the back-end services, so we should inject custom code between the services and API gateways to achieve this, which would result other challenges.
At the same time, as developers when we get a new tool we’re excited about it, and we often fall into the ‘if all you have is a hammer, everything looks like a nail‘ paradigm. It’s better to avoid this.
Let’s see some practical stuff; in fact, what kind of business logic the modern API gateways can include? For example, if we take the gateway service offered in Azure API Management (APIM), it is enriched with high degree of programmable request/response pipeline.
Below APIM policy, I have provided an authorization template based on the role based claims.
The API gateway decides the authorization to the endpoints based on the role based claims. The sections are commented, first it validates the incoming JWT token, then sets the role claim in the context variable and finally handle authorization to the endpoints based on the role claim.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Note: This is a thick API gateway implementation and the pros and cons of this is subject to the problem in hand. This above is a practical elaboration of one thick API implementation.
Scheduled jobs are common in software systems, most of them perform some kind of a network or data related activity, outside the main execution context and triggered based on a timer event.
There are several options available in Azure to implement scheduled jobs.
Serverless options
Azure Scheduler
Azure Batch
Custom code in VMs
Before digging into the details, first rule of design in my space, I always advocate the developers not use scheduled events in any case that you can trigger it using any other trigger. I agree that in certain cases the scheduled jobs cannot be avoided like a nightly data loading job from an OLTP to a data warehouse or your nightly builds but checking a folder for a file can be triggered using a different event rather than checking it in intervals.
Now let’s see the different available options.
Serverless
Azure has two different serverless offerings, Azure Functions and Logic Apps. Both can handle timer based triggers.
Azure Functions are straight forward, you can specify a cron expression on the timer trigger and write your code and deploy. Done! You can do this either from Visual Studio or in the ‘integrate’ section of your function in the portal. In the code it is set as follows.
public static class Function1
{
[FunctionName("Function1")]
public static void Run([TimerTrigger("0 */5 * * * *")]TimerInfo myTimer, TraceWriter log)
{
log.Info($"C# Timer trigger function executed at: {DateTime.Now}");
}
}
We can configure the scheduled jobs in Azure Logic Apps using the recurrence trigger as shown below. Logic Apps designer is straight forward and we can configure the recurrence timer trigger and schedule the following actions.
Azure Scheduler
Azure Scheduler is a PaaS based scheduler. This is a packaged consumption model of the scheduled tasks, but this has limited actions.
You can use HTTP/HTTPS calls or put a message in a Storage Queue, or put a message in Service Bus topic/queue. The HTTP/HTTPS can be used to communicate with external APIs in a schedule. The serverless triggers greatly make the Azure Scheduler obsolete, the recurrence logic has good customization out of the box, but again the functionality can be easily added in the serverless model.
Azure Scheduler had been used heavily before the serverless options were available. Especially PaaS developers used this approach in order to trigger timer actions by simply using HTTP/HTTPS triggers and hit backend services to execute the logic. Now, this is a high time to consider the rewrite of those schedule jobs using serverless model.
Azure Batch
Azure Batch provides the infrastructure for the batch processing. Azure offers this to use cheap computation for the batch processing jobs and also for computation heavy processing. Though the main intention of Azure Batch is not running a scheduled task in for an application, the application specific jobs can be submitted to the Azure Batch and executed on a schedule.
Example, in a HR application running on Web Apps require to process large amounts of data at the end of every month to calculate the wages could be a Azure Batch task which runs every month.
Custom code in VMs
This is the traditional approach. If you’re using IaaS then this option will not make you feel outdated. Also, in certain cases you would need this especially when your scheduled job requires some libraries or frameworks which require VMs. You can write the code and execute them as cron jobs in Linux VMs or as a process using Task Scheduler in Windows VMs. In Windows you can also use Windows Services for the schedule jobs.
Do not use Windows services unless you require your logic to be executed outside the system context. Most of the scheduled jobs can be run as tasks using Task Scheduler.
Cloud has the proven promise of great opportunities and agility for ISVs. Modern cloud platforms have low entry barriers and huge array of service offerings beyond traditional enterprise application requirements. Cloud services provide intact environment to SaaS applications with features such as cutting edge innovative services, intelligence as services, continuous integration and continuous delivery, computation and storage scale for the global reach.
The current digitized environment, device proliferation and the span of intelligent cloud services give the best mix of social, technical and business aspects for SaaS products to emerge and prevail with high success.
Cloud enables equal opportunity to every SaaS player – technical and business domain skills and expertise are vital elements in order to succeed in the SaaS playground, knowing the business and knowing the technology are two utmost important facts.
From a SaaS consumer point of view, a customer has ample number of choices available to choose from list of SaaS providers. Having the right mix of features, availability, security and business model is important. Choosing the right tools at the right time at the right cost is the skill to master.
Figure 1: What customers expect from SaaS providers.
Source: Frost & Sullivan, 2017
In order to deliver successful SaaS application, ISVs should have attributes such as – concrete DevOpspractices to deliver features and fixes seamlessly, responsible SaaS adoption models concerning Administration&Shadow IT, trust and the privacy of Data & Encryption, promising service Uptime and many more.
DevOps with Azure Tooling
Azure tools bring agile development practices and continuous integration & continuous delivery. Code changes take immediate effect in the build pipeline with VSTS build definitions and deployed to the respective environments in Azure.
Figure 2: The simple DevOps model with Azure tooling
Environment and resource provisioning is handled via automated ARM template deployments from VSTS build and release pipeline. The model depicted in Figure 2 vary based on the context and complexity of the project with multiple environments, workflows and different services.
Customers have the concern of how the SaaS enables the centralized organizational access management can be performed. On the other hand, SaaS providers require frictionless approach in the adoption of the services and enable more users much as possible.
Azure based organizational SaaS implementations often utilize Azure Active Directory (AAD) based integration and Single Sign On (SSO).
Customers trust the SaaS providers with their data. It is the most valuable asset SaaS providers take responsibility of in delivering value and helping the business of the customers. Data security and encryption is a prime concern and growing rapidly with complex and fast evolving regulatory and complaince requirements.
Azure has great compliancy support, tools and services in data protection. It offers many out of the box data encryption and protection services like TDE, DDM (Dynamic Data Masking), RLS (Row Level Security), In-built blob encryption and etc.
In certain cases, built-in security features do not provide the sufficient protection and compliance. In those sensitive environments we can leverage additional Azure services which provide high degree data security.
Figure 3: Advanced data security implementation in Azure
Azure Key Vault based encryption with SQL Database Always Encrypted, Blob encryption (envelope encryption), AAD based access control and MFA can be implemented in such cases. Also, this provides new models of Bring Your Own Key (BYOK) in encryption where customers can provide and manage their keys.
Service uptime should be considered not only during unexpected failures but also during updates.
Azure provides inbuilt geo replication for databases, storage and specific services. Application tier redundancy is implemented with the use of Traffic Manager. Configuring geo replication and redundancy introduces concerns like geographic regulatory concerns of data, synchronization issues and performance.
Azure tools like Application Insights for application monitoring & telemetry, auto scaling, geo replication, traffic manager and many others are mixed with architectural practices to deliver required uptime for the SaaS application.
Conclusion
Apart from the technologies and tools, SaaS application development on a cloud platform requires expertise on the platform of choice, in order to achieve cost effectiveness, business agility and innovation.
How SaaS application is bundled and sold is a crucial decision in technology strategies like cache priming, tenant isolation, security aspects, centralized security, multi-tenancy at different services and etc.
This article provides a high level of view about the considerations customers look from SaaS providers and how Azure tools and services can help in achieving them.
We keep the credentials and other secrets of the application in the source files. These secrets are visible to developers and being pushed to the source control. In order to avoid this, we can keep the secrets in centralized key management systems – but the credentials of the centralized key management system should be kept in the source files, resulting that at least one credential being placed in the source files.
Azure Managed Service Identity (MSI) solves this bootstrap problem. It eliminates the need of storing any credentials in the source files.
MSI is supported by different Azure services. This post explains how to set up MSI in the Azure Web App and retrieve a secret stored in Azure Key Vault (a database password).
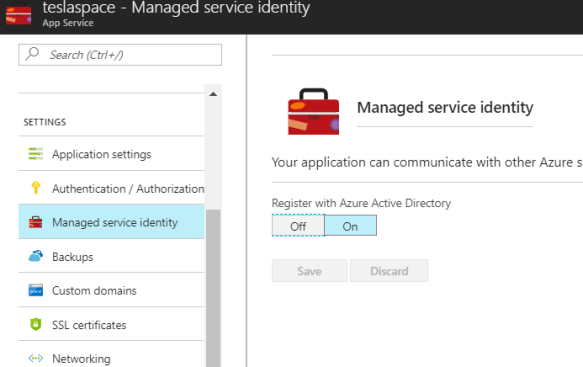
Setting MSI in Azure Web App
MSI works on Azure AD authentication. When MSI is enabled in a service (web app) it creates an application principle in the same tenant where the subscription of the Web App is attached to.
Navigate to your Web App, select the Managed Service Identity option and switch the feature ON.
This will create an application principle in the AAD with the same name of the Web App (teslaspace).
You can also notice the following section with the specific IDs in the ARM template of Web App.
Creating Azure Key Vault and set up Developer Access for Secrets
Now we should create a Azure Key Vault in a subscription attached to the same tenant. We will store our credentials and other sensitive strings in this Key Vault.
Creating a Azure Key Vault is straight forward and it can easily be done via the portal. I have skipped those steps in this post. Read more articles about Azure Key Vault
Once the Key Vault is created, we should add the Web App Service Principle to the Key Vault access policies. Give minimum permissions are possible.
This principle is given only Get permissions to the secret. This is enough to retrieve a sensitive string from Azure Key Vault.
We should create a secret in the Azure Key Vault and obtain the secret URI.
Navigate to the secret and copy the URI. Secret URIs are in the below format
This created a service principle in the corresponding tenant
We created a Azure Key vault
We granted some permissions to the Web App Service Principle
We created a secret in Key Vault and obtained the URI
Now, the MSI enabled Web App should connect to the Azure Key Vault and obtain the value of the secret. In order to connect to the Key Vault it does not require any credentials to be stored in the source code.
There is a NuGet package which facilitates this process.
The below code will retrieve the secret for you, ex – a db password
public async Task<string> RetrieveSecretBasedOnMSIAsync()
{
AzureServiceTokenProvider azureServiceTokenProvider = new AzureServiceTokenProvider();
string accessToken = await azureServiceTokenProvider.GetAccessTokenAsync("https://management.azure.com/");
var kv = new KeyVaultClient(new KeyVaultClient.AuthenticationCallback(azureServiceTokenProvider.KeyVaultTokenCallback));
var secret = await kv.GetSecretAsync("secret uri");
return secret.Value;
}
If you turn off the MSI from the Web App the above code will throw an exception that it cannot authenticate to the AAD.
Developer Environment
The above works in the production as MSI is enabled in the Web App, but how to set the same configuration in the developer machine and make sure that the authentication happens to AAD via the above code.
Also, we need a user principle to authenticate to the AAD. The same principle should be added to the Azure Key Vault with the required permissions (Get permissions for the secrets).
So create a user in AAD. ex – dev1@massroverdev.onmicrosoft.com. Add the user principle to the Key Vault as shown above. You don’t need to assign any subscription access to this user.
That’s all we should do in the Azure. In the developer machine, after installing the Azure CLI 2.0 or above, login to the Azure CLI using below command.
az login --allow-no-subscriptions
This will pop up the device login and complete the login using the credentials of the created user.
Note : You have to provide the — allow-no-subscriptions flag since user does not have any subscription level access. This is the bare minimum developer permission that can be given in MSI.
As long as the developer is logged in to the Azure CLI which has the required permissions in the Azure Key Vault, the above code will work.
Things to note
MSI service principle is a AAD V1 approach. V2 or MSAL support is yet to be released. So if you’ve a V2 app registration, enabling MSI will create another V1 application in the tenant. Read more
Developer gets to see the secrets during debug. There are workarounds to eliminate this.
Use a different KV in production environment
User a token based access for the service which have AAD authentication. This is possible in SQL Databases. But it adds additional complexity in handling tokens expiry and etc. Read more
First let me begin with ‘What is meant by Shadow IT ?’. In a broader view shadow IT is, any sort of IT usage without the direct governance of IT department of your organization.
Sometimes this remains as a violation of the company policies, but the proliferation of the cloud SaaS applications and BYOD trends makes shadow IT an unavoidable practice.
A simple example would be a cloud based file sharing application used in an organization which is not officially approved by the IT.
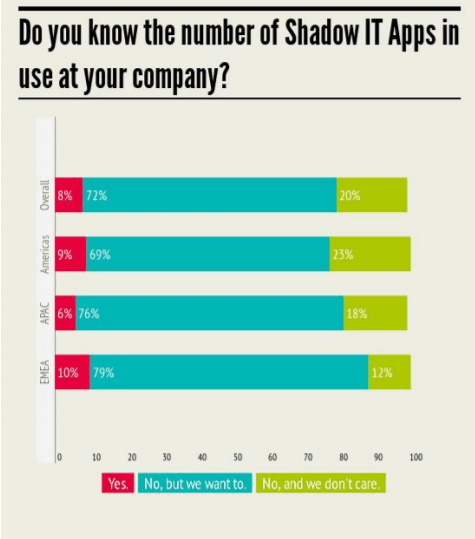
In most cases organizations are not aware of the tools used by their employees and shadow IT usage. Only 8% of the organizations are aware of their shadow IT usage.
In my opinion there are two major reasons which fuel the increasing shadow IT practices. First, when employees have higher and diversified devices than the ones available at work. Secondly when they find sophisticated SaaS tools than the ones available at work.
Another notable reason is – communication between contextual boundaries, like departments, SBUs and other companies – people tend to use cloud based SaaS tools either for convenience or due to some already existing shadow IT practices of a party.
How to with AAD V2
So, what is the importance in software development in shadow IT ? – One of the projects I’m involved with has been going through the transformation of being an internal system to a public system. We decided to open this up as a SaaS tool that anyone with a Azure Active Directory (AAD) credential can use it.
Behind the scenes the application has rules to track the user, tenant, recurrence of the tenant, other users in the tenant and the list grows. But anyone with a valid AAD account can simply create an account and start using it. This makes the application a perfectly fitted candidate in Shadow IT. It’s a perfect Shadow IT tool.
As SaaS provider we want many users as possible using our system, after all we charge per transaction 🙂
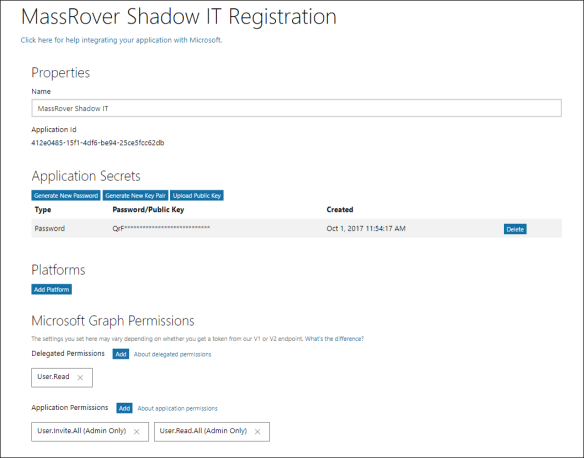
The application is registered as a AAD V2 app in the home directory.
We removed the friction in the enrollment by keeping only the minimal delegated permission (User.Read) in the app.
But in order to provide more sophisticated experience inside the application we require access to AAD and read permissions on other users. In order obtain this we thought of an approved shadow IT practice via application permissions.
We added the admin privileges to the application permissions, and generated application secrets.
The configured AAD V2 app principle look similar to the below one.
In the experience point of view, we trigger the typical following normal AAD login URL for the user login. We trigger the organization endpoint (restrict the Microsoft accounts) with the following URL. (You can try the URL)
This will popup the login and after the successful validation of the credentials you’ll see the following consent screen.
User accepts the consent and she’s inside the SaaS application Shadow IT begins here. In order to get the additional rights we allow the user to inform her IT administrator and ask for additional permission.
IT administrator will be notified by the email entered by the user with following admin consent link.
Here we obtain the tenant id from the id_token from the user logged in previous step. When the IT administrator who has admin rights in the AAD hits the above URL and after successful validation of the credentials he will see the following admin consent screen.
The permission list varies based on the configured application permissions in the application. After successful consent grant, the redirection will happen to a URL similar like this
Now the application can use the app secret to access the specific tenant.
Note: From AAD principle point of view, the service principle of the application is registered in the tenant in the first step. (This configuration should be allowed in AAD – by default this is enabled) and during the admin consent process the service principle gets more permissions granted to it.
Summary
We achieved both the frictionless experience for the user and allowing administrator to grant the permission when required. The below image summarizes the process.
By request IT admin knows the usage of application and it give some light to the usage of such SaaS.
By granting access IT admin allows it to the organizational use and removing shadow IT context.
If admin rejects the consent the organizational user knows that he’s in Shadow IT context.
Blocking of such SaaS may continue based on the organizational policies.









 Source: Frost & Sullivan, 2017
Source: Frost & Sullivan, 2017